概要
- LINEから36億パラメータの日本語言語モデルが公開されました。
- LINE Engineering Blog:https://engineering.linecorp.com/ja/blog/3.6-billion-parameter-japanese-language-model
- streamlitでrinna,LINEの日本語言語モデルを比較し、チャットっぽく表現します。
ソースコード
- メインのソースコード
- rinnaとLINEの日本語言語モデルを呼び出して、streamlitで比較しています。
- CPUで動くはずですが、結構重いです。
main.py
from module.rinna import Rinna
from module.line_llm import LineLLM
import streamlit as st
@st.cache_resource
def load_model_r():
rinna = Rinna(use_cuda=False)
return rinna
@st.cache_resource
def load_model_l():
line_llm = LineLLM(use_cuda=False)
return line_llm
def build_streamlit():
rinna = load_model_r()
line_llm = load_model_l()
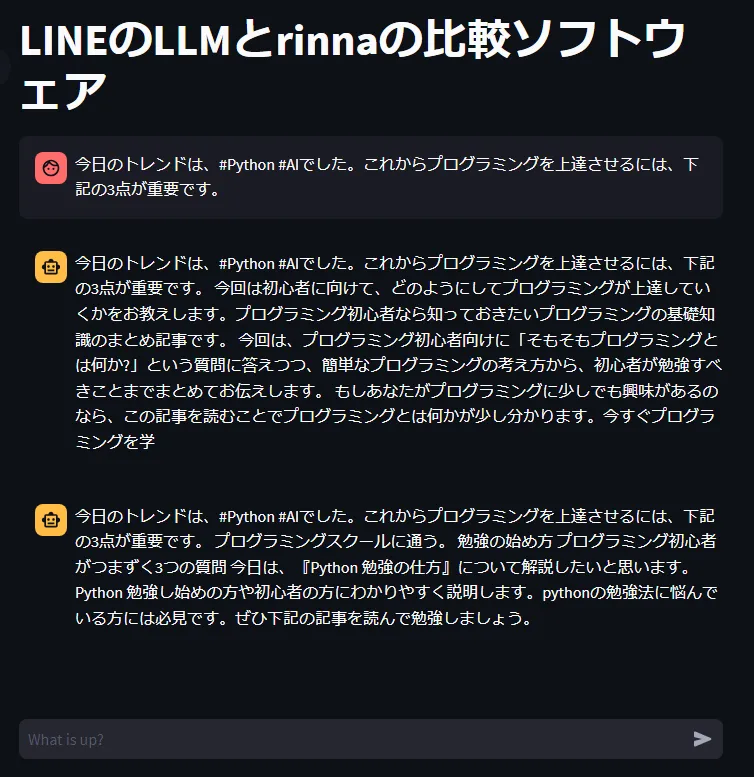
st.title("LINEのLLMとrinnaの比較ソフトウェア")
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# React to user input
if prompt := st.chat_input("What is up?"):
# Display user message in chat message container
st.chat_message("user").markdown(prompt)
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": prompt})
response = f"Echo: {prompt}"
# Display assistant response in chat message container
with st.chat_message("assistant"):
st.markdown(rinna.talk(prompt=prompt))
# Add assistant response to chat history
st.session_state.messages.append({"role": "assistant", "content": response})
with st.chat_message("assistant"):
st.markdown(line_llm.talk(prompt=prompt))
# Add assistant response to chat history
st.session_state.messages.append({"role": "assistant", "content": response})
if __name__ == "__main__":
build_streamlit()
- 下記2つのソースコードで、rinnaとLINEの日本語言語モデルをクラスにしています。
- デフォルトでは、CPUで動きますがかなり重いです。
- use_cudaをTrueにすることで、GPUモードで動きますが、GPUメモリが8GB以上は必須かと思います。
module.rinna.py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
class Rinna:
def __init__(self,model_name="rinna/japanese-gpt-neox-3.6b",torch_dtype=torch.float32,use_cuda=True):
self.model_name = model_name
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name, use_fast=False)
self.model = AutoModelForCausalLM.from_pretrained(self.model_name, torch_dtype=torch_dtype)
if torch.cuda.is_available() and use_cuda:
self.model = self.model.to("cuda")
def _process(self,prompt):
token_ids = self.tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = self.model.generate(
token_ids.to(self.model.device),
max_new_tokens=100,
min_new_tokens=100,
do_sample=True,
temperature=1.0,
top_p=0.95,
pad_token_id=self.tokenizer.pad_token_id,
bos_token_id=self.tokenizer.bos_token_id,
eos_token_id=self.tokenizer.eos_token_id
)
output = self.tokenizer.decode(output_ids.tolist() [0])
print(output)
return output
def talk(self,prompt):
text = self._process(prompt)
return text
module.line_llm.py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline, set_seed
class LineLLM:
def __init__(self,model_name="line-corporation/japanese-large-lm-3.6b",torch_dtype=torch.float32,use_cuda=True):
self.model_name = model_name
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name, use_fast=False)
self.model = AutoModelForCausalLM.from_pretrained(self.model_name, torch_dtype=torch_dtype)
if torch.cuda.is_available() and use_cuda:
self.model = self.model.to("cuda")
def _process(self,prompt):
generator = pipeline("text-generation", model=self.model, tokenizer=self.tokenizer, device=0)
set_seed(101)
text = generator(
prompt,
max_length=100,
do_sample=True,
pad_token_id=self.tokenizer.pad_token_id,
# num_return_sequences=5,
)
return text
def talk(self,prompt):
text = self._process(prompt)
return text[0]['generated_text']