【BERT】HuggingFaceのBERTモデルでネガポジ分析してみる【Python】
BERTモデルを使って、入力された文章のネガポジ分析してみました。
概要
- BERTを使って入力された文章のネガポジ分析をしてみました。
- attentionの可視化まで行きたかったけど、とりあえず、ネガポジ分析まで
ソースコード
pip install fugashi[unidic-lite]でfugashiをインストールする必要があります。
from transformers import TextClassificationPipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer
import torch
import plotly.express as px
import pandas as pd
class DocmentsAnalysis:
def __init__(self, model="christian-phu/bert-finetuned-japanese-sentiment",
tokenizer="cl-tohoku/bert-large-japanese-v2"):
self.tokenizer = BertJapaneseTokenizer.from_pretrained(
tokenizer,
# output_attentions=True,
do_subword_tokenize=True, #未知の用語をサブワードに分割します
word_tokenizer_type="mecab",
mecab_kwargs={"mecab_dic": "unidic_lite"} #mecabでunidic_liteという辞書を使います。
)
print(f"{tokenizer}:loaded")
self.model = AutoModelForSequenceClassification.from_pretrained(
model,
output_attentions=True)
print(f"{model}:loaded")
# self.pipe = TextClassificationPipelineAddOutputs(model=self.model, tokenizer=self.tokenizer)
self.pipe = TextClassificationPipeline(model=self.model, tokenizer=self.tokenizer, top_k=None)
print(f"pipeline generated")
if __name__ == "__main__":
da = DocmentsAnalysis()
line = ["最高の週末を過ごせました。"]
outputs = da.pipe(line)
print(outputs)
df = pd.DataFrame(outputs [0]) [["label", "score"]]
px.pie(df, values="score", names="label").show()
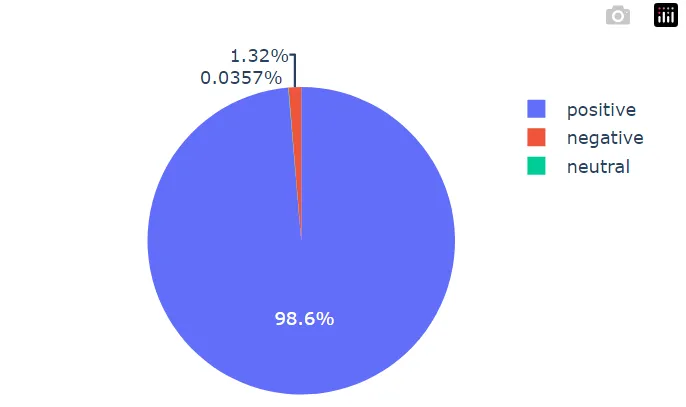
- アウトプットはこんな感じ
cl-tohoku/bert-large-japanese-v2:loaded
christian-phu/bert-finetuned-japanese-sentiment:loaded
pipeline generated
[[{'label': 'positive', 'score': 0.986445963382721}, {'label': 'negative', 'score': 0.013197273015975952}, {'label': 'neutral', 'score': 0.00035684832255356014}]]